Naive parallelism with HLVM

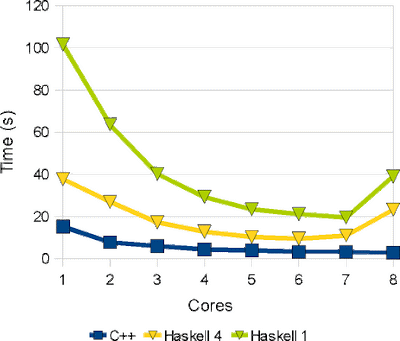
The latest OCaml Journal article High-performance parallel programming with HLVM (23rd January 2010) described a simple but effective parallelization of the HLVM implementation of the ray tracer. Comparing with similarly naive parallelizations of the fastest serial implementations in C++ and Haskell, we obtained the following results: These results exhibit several interesting characteristics: Even the naive parallelization in C++ is significantly faster than HLVM and Haskell. C++ and HLVM scale well, with performance improving as more cores are used. Despite having serial performance competitive with HLVM, the naively-parallelized Haskell scales poorly. In particular, Haskell failed to obtain a competitive speedup with up to 5 cores and its performance even degraded significantly beyond 5 cores, running 4.4× slower than C++ on 7 cores. The efficiency of the parallelization can be quantified as the speed of the parallel version on multiple cores relative to its speed on a single core:...